Many billions have been poured into the business relating to AI processor growth. For those who had been to record the variety of AI processors presently in growth or manufacturing at the wide range of start-ups, then that quantity rapidly surpasses 50 and is seemingly ceaselessly rising. Every one in every of these firms is aiming to construct a compelling product to fulfill the wants of their supposed clients, all the way in which from small-scale inference workloads as much as multi-datacenter scale coaching. One in every of these firms is Tenstorrent, led by CEO Ljubisa Bajic, who just lately employed famed chip designer Jim Keller because the CTO. Jim was additionally the preliminary angel investor when the corporate began. As we speak we're interviewing these two in regards to the firm, the Tenstorrent product, and the route of the calls for for machine studying accelerators.

This interview was considerably sudden – a couple of month in the past Jim Keller reached out to me to ask if we needed to interview him and Ljubisa in regards to the firm. We had highlighted at the beginning of the 12 months when Jim was employed by Tenstorrent, and I’ve sat by means of various Tenstorrent displays by Ljubisa and his staff, so no matter firm Jim lands at will get quite a lot of consideration. Apparently my title was advisable to succeed in out for an interview, and right here we're!
We truly break up the interview into two segments. That is the primary 90-minute interview transcription, on the subject of Tenstorrent with Ljubisa and Jim. There can be a second 90-minute interview to observe, on the subject of Jim Keller, subsequent week.
 Ljubisa Bajic CEO Tenstorrent |
 Jim Keller CTO Tenstorrent |
 Ian Cutress AnandTech |
Ljubisa Bajic is a veteran of the semiconductor business, working extensively in VLSI design and debug coupled with in depth accelerator structure and software program expertise. Ljubisa spent a decade inside AMD as an ASIC architect engaged on energy administration and DSP design, earlier than a spell at NVIDIA as a senior architect, after which again to AMD for a few years working with Jim on the {hardware} that powers AMD’s steadiness sheet in the present day. He left AMD to start out Tenstorrent with two different co-founders in 2016, has raised $240m in three rounds of funding, and created three generations of processors, the newest of which is transport this 12 months. No less than two extra generations are on the way in which.
Jim Keller has typically been described as a {hardware} ninja, or a semiconductor rockstar. His profession is filled with profitable silicon designs, such because the DEC Alpha processors, AMD K7/K8, HyperTransport, Apple’s A4/A5 processors, AMD Zen household, Tesla’s Absolutely Self-Driving chip, and one thing essential at Intel (most likely). He now sits as CTO for Tenstorrent, engaged on the corporate’s next-generation processors for 2023 and past.
Tenstorrent is a pure-play fab-less AI chip design and software program firm, which signifies that they create and design silicon for machine studying, then use a foundry to make the {hardware}, then work with companions to create options (as in, chips + system + software program + optimizations for that buyer). For those who know this area, this makes the corporate sound like all of the opposite 50 firms out available in the market that appear to be doing the identical factor. The standard break up with pure-play fabless AI chip design firms is whether or not they're targeted on coaching or inference: Tenstorrent does each, and is already within the means of finalizing its third-generation processor.
IC: Who or what's Tenstorrent, in your personal phrases?
LB: Tenstorrent is a start-up firm engaged on new laptop architectures which might be aiming to primarily be the suitable substrate for executing machine studying workloads. Extra data-heavy workloads have been rising and taking up, particularly the datacenter computing scene, however we wish to go wider than that as properly.
IC: Jim, you had been the primary investor in Tenstorrent - I keep in mind you telling me a short while in the past, whenever you joined the corporate 5 months in the past. What's it about Tenstorrent that’s actually obtained you excited and ?
JK: So I do know Ljubisa, and I’d seen quite a lot of AI start-ups. Once I was at Tesla, all people got here to speak to us and pitch their stuff, and there appeared to be an odd assortment of strange concepts. [There were] individuals who didn’t actually get the total finish of chip design, the software program design, and all of that. I do know Ljubisa – he has truly labored on GPUs in actual chips and he ran a software program staff, and he truly understands the mathematics behind AI, which is a considerably uncommon mixture. I truly instructed him, I believed it might be humorous if he had a few guys working in a basement for a 12 months, and so I gave him what’s known as the Angel Spherical of funding, they usually truly did. You had been in a basement or had been you over a storage or one thing?
LB: We had been in a basement!
JK: You had been actually in a basement so, they usually constructed a prototype utilizing an FPGA that obtained the seen spherical, after which that obtained him additional to get the primary day spherical.
IC: So was the basement in Toronto, so far as I do know, you’re primarily based in Toronto?
LB: Sure, it was the basement of my home, primarily the identical basement I’m sitting in proper now. I’ve come full circle, 5 years later!
JK: And the opposite factor I instructed him - make certain no matter you’re constructing at all times has software program to run on it. There have been various AI efforts the place they construct a chip, after which they are saying ‘now we’re going to construct the software program’. They then discover out the {hardware}/software program interface is horrible, and it’s troublesome to make that work. I believe [Tenstorrent] did an fascinating job on that.
I used to be speaking to our compiler guys just lately they usually’re doing the third re-write of the software program stack, which is definitely nice as a result of the {hardware} is fairly good for software program. They’ve had concepts, and it obtained to a sure level, after which they re-wrote it. The brand new rewrite is definitely lovely, which I believe on the planet of AI software program, there’s not a lot lovely AI software program down that talks to the {hardware}.
IC: To come back again to Ljubisa and the basement - Tenstorrent has three co-founders, was it simply the three of you in these early days?
LB: So it was two of us for the primary few months, then our third co-founder joined us proper round that point Jim made the funding into Tenstorrent, type of making the entire thing a little bit extra official, and a little bit bit much less of a pipe dream. So a number of months after that, we moved out of the basement and obtained an workplace which was once more, a really typical, a really low-end workplace in a foul a part of Toronto with shootings.
JK: Shootings in Toronto?
LB: Yeah, search for a foul a part of city in Toronto! We had been there for some time, it was quite a lot of enjoyable on reflection.
IC: So that you’d spent the very best a part of a decade at AMD, a little bit time at NVIDIA, what made you resolve to leap and kind your personal start-up?
LB: Effectively I actually needed to construct a next-generation laptop which was going to depart a dent of some type on the pc scene. The issue materialized, which was machine studying. So I began Tenstorrent in 2016, and by then it was clear that this was an enormous workload, that it was going to be a serious upheaval, that it was going to be an web grade revolution to our widespread area.
It’s troublesome to make giant departures off of what’s already there at massive firms. That’s a part of it. The opposite a part of it was that resulting from utterly unrelated causes, I made a decision to maneuver on and see what to do. You place the 2 collectively and in some unspecified time in the future Tenstorrent obtained conceived of as an concept. It was very wobbly at first, so the primary month or two I used to be fascinated by it. I used to be very unsure that it was actually going to go wherever, and the factor that basically kicked it over was that Jim confirmed belief within the concept. He confirmed belief in my potential to do such a factor, like actually in a really possible way. If Jim had not invested, I don’t suppose we'd have actually gone ahead. In all probability I'd have simply gone on to get one other job.
IC: So the 2 of you met collectively at AMD, engaged on tasks collectively. I’ll begin with you Jim, what was your first impression of Ljubisa working with him?
JK: Ljubisa is an enormous hulking man, so we’re on this assembly and you recognize, all these nerdy engineers are speaking and there’s Ljubisa saying that is how we must always do stuff. He has, let’s say, a reasonably forceful character and he’d executed an entire bunch of labor on bettering energy effectivity of GPUs. When he first proposed that work, there was a little bit of pushback, after which he slowly labored it out and he was proper. I believe Raja Koduri truly instructed him in a while that quite a lot of the facility/efficiency enchancment they obtained got here from the work he did.
Then he took over the staff of software program energy administration and system administration, which had been form of put collectively from a few totally different teams and it wasn’t very useful. Then he did a reasonably vital transformation of that by way of the constitution, and likewise effectiveness. So I used to be type of watching this go on.
Once I was at AMD, the merchandise that they had (on the time) weren’t superb, and we actually canceled the whole lot they had been doing and restructured stuff and created a bunch of fresh slate alternatives. Zen was, on the high degree, actually a clear slate design. We reset the CAD flows, Ljubisa was resetting the facility administration technique and a few different issues, so he was one in every of my companions in crime by way of altering how we do stuff. I don’t suppose you had been a senior fellow, I discovered the very best senior fellows at AMD, no less than I believed they had been the very best, they usually labored for me. I had a little bit gang, after which Ljubisa joined that gang, as a result of all people mentioned he’s one in every of us. That was fairly cool, after which collectively we may mainly get any technical downside transferring as a result of we had fairly good alignment, in order that was actually enjoyable.
IC: Identical query to you Ljubisa. Jim is a widely known title within the business for semiconductor design, and he got here into AMD type of laying down the hammer – to tear the whole lot up and begin a clear slate. What was your impression of him at that time?
LB: On my second chart at AMD, I re-joined the corporate having explicitly determined that I used to be going to primarily apply no matter vitality I’ve obtained into fixing the whole lot in my sight, and balk at nothing. I joined with that mindset, and I didn’t know Jim on the time. However fairly rapidly we intersected and likewise it grew to become fairly clear to me that alone, no matter my enthusiasm and design to make quite a lot of affect, it was going to be troublesome to get round all of the obstacles that you just typically come across whenever you wish to have an effect on quite a lot of change in a corporation of that dimension.
My first impression was that Jim was primarily completely bulldozing (Ian: Ha!) by means of something that you might characterize as any type of impediment, whether or not it was like organizational or technical, like actually each downside that will land in entrance of him, he would simply form of drive proper over it with what appeared like no form of slowdown in any respect. So given my disposition of what he was already doing, I believe that’s in the end, no less than part of, what led us stepping into alignment so rapidly and me stepping into this group that Jim simply talked about.
I wasn’t a Senior Fellow, I used to be truly a director - all people on the time stored saying that no person understands why I’m solely a director and why am I not a fellow, or a senior fellow. That was a typical theme there, however I suppose I match in additional with these technical of us they usually mentioned there are quite a lot of organizational challenges to getting something critical executed. I believed that it was higher [for me to be] positioned someplace you have got a little bit of attain into each.
For me the most important preliminary impression was that Jim enabled the whole lot that I needed to do, and mainly acknowledged and he did this for anyone that was in his orbit. He’s extraordinarily good at choosing individuals that may get stuff executed versus individuals that may’t, after which primarily giving them no matter backing they want to try this.
As we began collectively, he began giving me all kinds of random recommendation. A narrative that I’ve talked about earlier than is that we had a gathering in Austin one time, and I used to be presupposed to fly on Tuesday morning. I went to check-in early and realized that I had booked the ticket for every week earlier. So I by no means went to the airport, I by no means had a resort, I didn’t have a flight. I known as up Jim and I mentioned ‘I obtained to purchase one other ticket and I can’t undergo the company programs as a result of I want to purchase it now and the flight is 6am the following morning’. So he goes ‘yeah, you must actually be careful for that - you’re type of too younger for this form of habits!’. I’ve gotten all kinds of life recommendation from him which I’ve felt was extraordinarily helpful and impactful for me. I’ve modified main issues in the way in which I'm going about doing stuff that’s obtained nothing to do with computer systems and processors primarily based off of Jim’s enter. He’s been an enormous affect – it began with work, nevertheless it goes deeper than that.
IC: Appropriate me if I’m mistaken, however for the time inside AMD, it type of seemed like Jim’s method or the freeway?
JK: I would not say that! The humorous factor was, we knew we had been type of on the finish of the highway - our clients weren’t shopping for our merchandise, and the stuff on the roadmap wasn’t any good. I didn’t should persuade individuals very a lot about that. There have been a number of individuals who mentioned ‘you don’t perceive Jim, we now have a chance to make 5%’. However we had been off by 2X, and we couldn’t catch up [going down that route]. So I made this chart that summarised that our plan was to ‘fall a little bit additional behind Intel yearly till we died’.
With Zen, we had been going to catch up in a single technology. There have been three teams of individuals - a small group believed it (that Zen would catch Intel in a single technology); a medium-sized group of those who thought if it occurs, it might be cool; then one other group that positively believed it was inconceivable. A number of these individuals laughed, and a few of them type of soldiered on, regardless of this perception. There was quite a lot of cognitive dissonance, however I discovered every kind of those who had been actually enthusiastic.
Mike Clark was the architect of Zen, and I made this record of issues we needed to do [for Zen]. I mentioned to Mike that if we did this it might be nice, so why don’t we do it? He mentioned that AMD may do it. My response was to ask why aren't we doing it - he mentioned that everyone else says it might be inconceivable. I took care of that half. It wasn’t simply me, there have been plenty of individuals concerned in Zen, nevertheless it was additionally about getting individuals out of the way in which that had been blocking it. It was enjoyable – as I’ve mentioned earlier than, laptop design must be enjoyable. I attempt to get individuals jazzed up about what we’re doing. I did every kind of loopy stuff to get individuals out of that type of desultory hopelessness that they had been falling into.
IC: Talking of enjoyable, in your scaled ML discuss, there have been quite a lot of feedback on there since you used Comedian Sans because the font.
JK: A buddy of mine thought that it might be actually humorous, and to be sincere, I didn’t actually know why. However I’ve gotten quite a lot of feedback about that. One of many feedback was that ‘Jim’s so bad-ass that he can use Comedian Sans’. I simply thought it was humorous. It was good as a result of they didn’t inform me who I used to be presenting to - I walked within the room and it was all bankers and traders and college bureaucrats. They instructed me it was a tech discuss and I believed ‘Oh, right here we go!’.
IC: The title of your discuss was ‘TBD’, I believed that was form of type of like an in-joke – ‘it’s the way forward for compute, so let’s name the discuss TBD’?
JK: I believe which may have been an in-joke!
IC: However talking of one thing enjoyable, so for Tenstorrent in 2016. On the time Jim was engaged on Tesla, on the self-driving stuff - whenever you had been talking to Ljubisa? On the time did Ljubisa have a concrete imaginative and prescient at that time? Was there one thing extra than simply who Ljubisa is, you recognize, gave you the impetus to take a position?
JK: There have been a few issues. One was that we had been all in that means of discovery about simply how low the precision of the arithmetic you wanted to make neural networks work. Ljubisa had provide you with a reasonably novel variable-precision floating-point compute unit that was actually dense per millimeter. He additionally had an structure of compute and information, after which how he needed to interconnect it which I believed was fairly cool. He had fairly sturdy concepts about how that labored. Pete Bannon and I talked to him a few instances whereas we had been at Tesla. The engine Ljubisa was constructing was truly extra refined than we (at Tesla) wanted.
Pete was the architect of the AI engine within the Tesla chip, and it’s good for working Caffe - simply superb. Half of the compiler staff for that chip was Pete! It’s as a result of, once more, the hardware-software match was so good, and Caffe produced a pseudo instruction set which you trivially modified to go run on the AI engine. What Ljubisa was doing was extra refined, to run plenty of totally different sorts of software program.
Ljubisa on the time was already aiming at PyTorch I believe? That was earlier than PyTorch was the winner, on the time when TensorFlow was main again then.
LB: At the moment PyTorch was simply known as Torch nonetheless, and TensorFlow had simply type of began being hyped. So Caffe was actually the dominant framework on the time and TensorFlow was on the horizon, however PyTorch was not fairly on the horizon.
JK: Caffe can describe extra complicated fashions, particularly whenever you go into coaching, and the engine we needed at Tesla didn’t want to try this. So we constructed a less complicated engine, however Ljubisa was already off to the races and he may present benchmarks and present good compute depth. The Tenstorrent guys had a hacked-up model of their software program that truly did one thing helpful. It was being attentive to {hardware}/software program boundaries even method early on within the design, and I believed that was key.
LB: We had a field that we had been taking round and exhibiting all people in June 2016. It was working neural networks end-to-end on Caffe on an FPGA and returning outcomes, and so it wasn’t something that would promote nevertheless it confirmed that we may mainly carry up this factor end-to-end comparatively rapidly and that we had a bunch of concepts. In the end it had all of our key focal factors, even now, or primarily stuff we needed from the get-go. It hasn’t been an enormous revolution in high-level pondering since then, it’s been extra only a large quantity of execution.
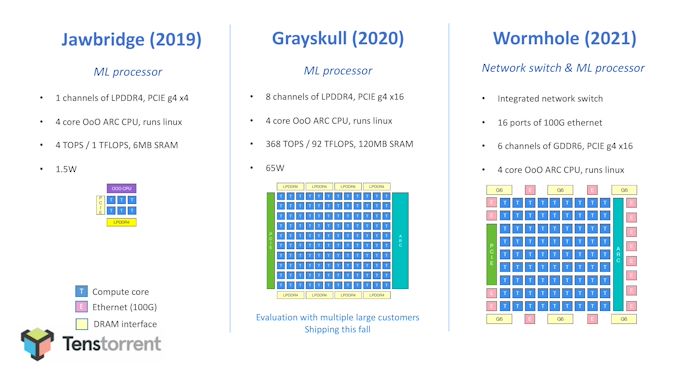
IC: The present outlay of Tenstorrent begins with the preliminary proof-of-concept Jawbridge design in 2019, with six Tensix cores and a small 1.5W design, main into a much bigger ‘Grayskull’ chip with 120 Tensix cores and PCIe 4. Grayskull is ready to ship to clients this 12 months. Many of the current AI start-ups haven’t publicized their ‘proof-of-concept’ designs, so are you able to clarify why it was essential to have such a quick follow-on from this primary mini-chip to the one which’s presently being offered?
LB: There have been two the reason why we went about our product roadmap the way in which we did. One was purely danger management- it was a brand new staff, no present flows, no present something. We actually needed to flush the pipe and get one thing constructed in order that the entire 50+ steps that it's good to put in place to get it executed could be executed. We've all of it working and we didn’t wish to run a danger of sinking a pile of cash in case there’s a mistake. The opposite motivation was that we imagine fairly deeply that it’s essential to have the identical structure mainly span from edge to large multi-chip, multi-computer deployments within the cloud. The primary cause why we predict you want an structure that spans so extensively is that as you go away from simply working by means of a bunch of equations, to implementing the neural internet, you get into extra fancy issues like runtime sparsity or dynamic computation or something that tries to go away from the mindset.
In any other case it turns into about simply crunching a bunch of multiplies, the identical multiplies each time, and also you naturally run into compatibility dynamics. So think about you find yourself with a state of affairs the place you practice one thing on an NVIDIA GPU, and the {hardware} has a 2X sparsity characteristic in case you apply a sure set of constraints to your information. For those who don’t have a suitable piece of {hardware} wherever you deploy this, both in a telephone, or an edge system, you'll lose that 2X. When it comes to sparsity, that 2X issue is simply going to develop anyway, in our view.
Basically we felt it was an enormous benefit to have the ability to clearly show that we will do a single watt chip. We are able to additionally do a 60-watt chip, and we will do an information middle filled with our chips related by means of the Ethernet that’s additionally on our chips. So whenever you take a look at this spectrum, the one watt chip was the simplest to do, so you recognize, it was one other level in favor of us doing it. It’s type of a crawl-walk-run state of affairs, however exhibits the entire spectrum.
JK: You recognize, lots of people spend a boatload of cash on their first strive. Grayskull (the chip transport this 12 months to clients) is our third-generation chip - we had that prototype in an FPGA as the primary technology, and had the take a look at chip as our second. The corporate has discovered a shit-load on every step, each {hardware} and software program. It’s mirrored within the software program stack, and our software program staff is fairly small.
I’ve seen quite a lot of AI firms who have gotten a chip again and their plan has been that to make it work they should rent 300 software program individuals. Which means they do not actually have a plan. You'll be able to’t actually overcome that mismatch within the {hardware}/software program boundary with enormous groups. Effectively at some degree you might, in case you can throw 1000 individuals at it, and a few persons are doing that. That’s not likely the suitable approach to do it, and that’s not going to be one thing you might expose long term to programmers, as a result of the complexities are so excessive, it will get actually fragile, after which the programmers can’t see how the {hardware} works.
One of many key components of Linux, in addition to open-source software program and working on x86, is that programmers may program the {hardware} proper to the metallic. They may see the way it labored and it was apparent, it was sturdy, and it labored over time. For AI {hardware} that’s too fragile to be uncovered to most programmers. Not all programmers, however you recognize, the ninjas.
IC: The character of AI is of course bi-furcated between coaching and inference, and the Greyskull chip could be very a lot marketed as an inference design. With so many firms focusing on the inference market, how a lot of a hit has it been? What’s been the pickup charge between firms evaluating vs firms deploying?
JK: We’ve began manufacturing, however there’s a lead time on that. Our plan is admittedly beginning in Q3 and This fall this 12 months. We’ve talked to an entire bunch of individuals, and after we present them the benchmarks, they’re excited. It’s sufficient for them to ask for a field of {hardware}!
After we can run it and do it, we’ll see the pickup on the distribution. On the inferencing facet, Ljubisa, what was your quantity? I believe we may have made the chip about 20%-30% extra environment friendly if it was inference solely. That delta is sufficiently small that in case you’re going to go deploy an entire bunch of AI {hardware}, reasonably than have two totally different units of {hardware} for inference and coaching, then the effectivity delta is sufficiently small to take care of compatibility between the 2. I believe we did a superb factor - Grayskull can do coaching, it’s going to benchmark very well on that, and with the following technology after that we now have extra networking between chips so we will scale up greater and higher. However they’re basically the identical structure, making it straightforward to leap to the newest.

Grayskull in PCIe
IC: Varied AI chips on the market are focusing on ease-of-deployment with simplified code set up, single-core designs, peak TOPs, or constant batch-1 efficiency. What makes the Grayskull processor the inference chip of selection for the purchasers?
LB: So purely on technical metrics, I believe it stacks up very properly versus different choices which might be obtainable on the market. The one factor that Grayskull can do, which I imagine no less than a lot of the options that I take a look at can't do, is conditional computation. This allows dynamic sparsity dealing with for AI.
So to make an instance, in case you’re doing coaching in the present day, for essentially the most half no person can use sparsity in any respect. The way in which sparsity will get used is that often you practice a mannequin with no assumption on sparsity. Finally you post-process it after the actual fact, and also you make quite a lot of weights for the mannequin zero, and it turns into type of a sparse mannequin for inference.
So we’re ready to make use of sparsity to our acquire throughout coaching. For instance, even throughout inference, the place most people deal with these weights, there's a trade-off in what number of you’re going to prune out and make zeros towards what sort of high quality you’ll be left with. We’re in a position to make use of sparsity in intermediate outcomes, in activations, in stuff that’s not recognized at compile time.
Lastly we’re in a position to do comparatively programmatic stuff in a neural community compute graph. We’re superb at having a bunch of heavy math-like matrix multiplies or convolutions or no matter, but when it’s adopted by a node that does one thing that’s utterly programmatic, we will try this on the chip. Our design will not be all about math density, it’s a sword – it allows extra normal programming. Each one in every of our cores has a set of RISC engines in it which might mainly run no matter you need on them.
So we imagine fairly deeply that as neural nets proceed evolving, each the dynamic sparsity and conditional computation, in addition to programming the graph, are going to be getting increasingly more essential. That is primarily as a result of simply placing in a bunch of pricey math has led to the biggest fashions to be data-center dimension, however then in case you don’t scale with any smarts, it's type of troublesome to maintain.
IC: By having this conditional computation in every of your cores, you’re sacrificing some die space. However you get extra flexibility throughout the compute stack throughout the mannequin utility?
LB: You get the flexibleness, positively. Including programmability isn’t free as traditional, so there’s a little bit of sacrifice there. However whenever you take a look at the uncooked numbers, let’s say the world of these RISC cores in comparison with the remainder of the block, is under 5%. Energy consumption is identical type of story. In the end in case you play your playing cards proper, what you pay doesn’t should be vastly noticeable within the die space of the whole lot that goes into this design. We predict we strike a superb steadiness.
IC: What verticals have been to date: cloud service suppliers, authorities, industrial?
JK: I believe there's one other method to have a look at it. The three massive areas of AI in the present day are picture processing, language processing and suggestion engines. Then there's additionally this motion from convolutional networks to transformer networks. Everyone's utilizing the identical constructing blocks. Then what we have observed is lots of people go and goal on the massive hyperscalers, however the hyperscalers received’t deploy them till you'll be able to promote them 1,000,000 components. However they do not wish to purchase 1,000,000 components till they see a proof-point of 100,000. These clients who need 100,000 wish to see a 10,000-unit deployment.
We have talked to an entire bunch of individuals, from the highest to the underside of the stack, they usually're all . Those which might be best to speak to which might be going to maneuver the quickest, like AI start-ups, or analysis labs inside of massive firms that personal their very own software program. They perceive their fashions and simply get on with it. Our preliminary goal is not to get some enormous contract, it's to get 100 programmers utilizing our {hardware}, programming it, and residing with it every single day. That is the place I wish to get to within the brief run, and that is mainly our preliminary plan.
However they're a reasonably numerous set of those who we're speaking to. There's the autonomous crowd, management programs, imaging, language. We're constructing this cool suggestion engine, which has an additional board and a pc with an enormous quantity of reminiscence to make that mannequin work. So it is pretty numerous, however we're in search of people who find themselves agile, versus any explicit vertical.
IC: Jim has been quoted as saying that the Tenstorrent design was ‘The Most Promising Structure Out There’. Are you able to shed some mild on what this meant on the time Jim initially invested? Was that extra in regards to the preliminary Grayskull inference design, or was there imaginative and prescient into the Wormhole processor (subsequent technology)?
JK: I'd begin with our stream. We've a compiler stack that begins with PyTorch producing a graph, after which the graph will get parallelized into smaller chunks. These chunks should coordinate between their computation, after which they execute kernels. That is the fundamental stream that everyone is doing. What we now have is a very nice {hardware} abstraction layer between the {hardware} and the software program that makes all that work, and that’s what I actually like.
[In the world of AI], in case you make a extremely massive matrix multiplier, the issue is that the larger it will get, the much less energy environment friendly it will get as a result of you need to transfer information farther. So you don't need the engine to be too massive, you need it to be sufficiently small to be environment friendly, however you don’t need it to be too small, as a result of then the chunk of knowledge it is engaged on is not that fascinating. So we picked a fairly good dimension of what we name our Tensix processor. The processor is fairly programmable. It is actually good at doing computation regionally in reminiscence, after which forwarding the information from Compute Engine to Compute Engine, in a method that is not software program disastrous.
I've seen individuals say that they've a DMA engine, and also you write all this code for it, however then they only find yourself spending their complete life debugging nook instances. [At Tenstorrent] we now have a very nice abstraction within the {hardware} that claims (i) do compute, (ii) when it's good to ship information to place the information within the pipe, (iii) whenever you push it within the pipe, the opposite finish pulls it out of the pipe. It is very clear. That has resulted in a reasonably small software program staff, and software program you'll be able to truly perceive.
So once I say that it's promising, it's as a result of they've an entire bunch of issues proper. The compute engines are the suitable dimension, it natively does matrix multiply and convolution (reasonably than writing for threads), and it natively is aware of the right way to talk information round. It is superb at conserving all the information on-chip. So we're rather more environment friendly on reminiscence - we do not want HBM to go quick!
Then after we hook up a number of chips, the communication on a single chip in comparison with the communication from chip to chip isn't any totally different on the software program layer. So whereas the bodily transport of knowledge is totally different on-chip with a NOC versus off-chip with Ethernet, the {hardware} is constructed in order that it seems like it's simply sending information from one engine to a different engine - the software program does not care. The one factor that does is the compiler, which is aware of the latency and bandwidth is a little bit totally different between the 2.
However once more, the abstraction layers are constructed correctly, which implies you do not have to have three totally different software program stacks. For those who write on a GPU, you need to be a CUDA programmer within the thread, then you need to coordinate throughout the streaming multiprocessor, then coordinate on the chip, then you have got NVLink which is a unique factor, after which you have got the community which is a unique factor. There are a lot of totally different software program layers in that mannequin, and you probably have 1000 individuals, or if that is what you suppose is enjoyable, that is cool.
However in case you simply wish to write AI software program, you do not wish to learn about all these totally different layers. We've a plan that truly will work.
We're additionally doing another fascinating issues. We're including general-purpose compute as a part of the graph and future merchandise, and we're the right way to make it programmer-friendly. We’re additionally asking programmers need they wish to do. I've executed quite a lot of tasks the place you construct the {hardware}, after which the software program guys don’t prefer it as a result of that is not what they needed. We try to fulfill the software program guys the place they're at, as a result of they only wish to write code. Additionally they wish to perceive the {hardware} to allow them to drive it, however they do not wish to be tortured by it.

IC: One of many issues once I converse to AI software program firms is that once they go from a computation on-chip to a multi-chip strategy, you need to break down the graph to have the ability to parallelize it throughout a number of chips. It appears like in your design, or within the next-generation Wormhole design no less than, you have got 16 x 100 gigabit Ethernet connections per chip to connect with a number of chips. From what I perceive right here, the programmer's perspective doesn’t change in the event that they’re engaged on one Wormhole or 100,000? The compilation is completed, and the software program stack continues to be simply the identical?
JK: Sure! We're truly constructing a 4U server field with 16 Grayskulls in it. For Greyskull we don’t have Ethernet however they're related with PCI Specific Gen 4. The compiler can break down a graph throughout these 16 components. The software program does not care if the transport is PCIe or Ethernet, however Ethernet is extra scalable in an enormous system so we switched to Ethernet for our subsequent technology extra scalable half. However we'll have the ability to take a coaching mannequin, have it robotically compile down the software program will do the graph, not the programmer.
IC: While you scale to a number of chips, there's clearly going to be a latency penalty distinction whenever you're transferring information between Tensix cores on-chip in comparison with off-chip. How does that issue into your design, after which from a software program degree, ought to the programmer care?
JK: This is the fascinating factor in regards to the computation. Matrix multiply is normally N3 computation over N2 components - because the footprint of the computation will get greater, the ratio of bandwidth goes down. We predict we now have the suitable ratio of bandwidth on Wormhole (next-gen 2022) in order that the computation could be very successfully utilized on chips properly because the 16 Ethernet ports that helps the communication between chips.
Then the issue comes all the way down to the graph. As an answer designer, you need to take into consideration the right way to decompose the issue after which the right way to coordinate it. That is all dealt with by our software program stack - the programmer does not should be concerned in that. The programmer can suppose extra about how they need their mannequin to look, and the compiler takes care of the right way to get the very best charge out on the chips.
IC: For each the present 2021 Grayskull chip and the long run 2022 Wormhole chip, they're type of on this form of 65 to 75 Watt boundary. As you scale out to 1000s of chips, the communication throughout the entire array turns into a serious a part of the facility dialogue, proper? Against this, in case you had been to have made 300-watt chips would you have the ability to maintain extra on die, and have much less energy could be wasted on communication. How do you marry the 2 between having a decrease energy chip, however a wider community array?
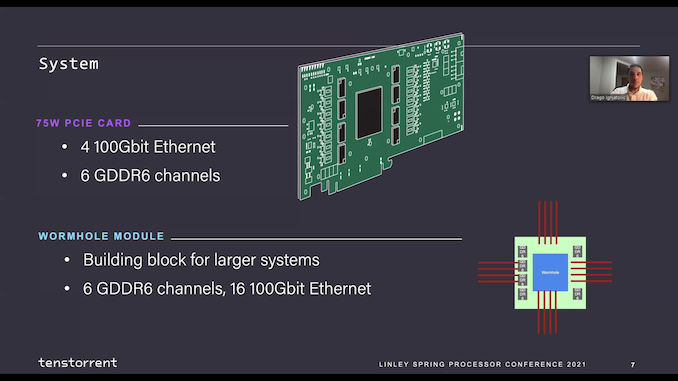
JK: We’re extra restricted by die dimension. The Grayskull and Wormhole chips are literally pretty giant. They’re on GlobalFoundries 12 nm. They're about 650 to 700 sq. millimeters?
LB: 620 mm2 (for Grayskull) and 670 mm2 (for Wormhole).
JK: So for Grayskull, we now have a 75-watt card. That’s the chip plus the DRAM and the whole lot else on the cardboard (so it’s not the chip that’s 75 watts). However we may additionally run it at 150 watts, at the next frequency, at the next voltage.
Then for the following technology past Wormhole, after we do a course of node shrink, we're elevating the frequency fairly a bit and the computational depth goes up. We're additionally shifting to the next bandwidth interconnect. It is a barely greater energy kind issue, nevertheless it's nonetheless lower than the present GPU type of roadmap.
One of many issues we do is since we maintain a lot of the reminiscence site visitors on-die we do not want the excessive bandwidth reminiscence, which has a excessive energy price. Then for the Ethernet stuff, you solely use actual energy whenever you're speaking. We are able to do some dynamic energy administration, such that if the community ports are all totally loaded we will decelerate the core a little bit bit to maintain it balanced. So the numbers on the quote spreadsheet all look fairly good.
You recognize actuality is enjoyable, as a result of we go construct these items and we'll study quite a bit. I've seen quite a bit as properly, and I anticipate that we'll get our ass kicked on a pair issues. We'll want we would executed this or that totally different. However the design and simulations we now have executed look fairly good.
IC: Isn’t there at all times low-hanging fruit with each chip design although?
JK: Oh yeah, I’ve by no means executed a challenge. Like I nonetheless keep in mind, Pete Bannon and I had been the architects of EV5, and after we had been executed it was the quickest microprocessor on the planet. I used to be so embarrassed about what I did mistaken [on that chip], I may barely discuss it. I knew each single downside. However they nonetheless put it within the Guinness Ebook of World Data. It is a humorous phenomenon, whenever you're designing stuff, since you are intimate with the small print - you discuss in regards to the cool stuff, however you recognize the whole lot.
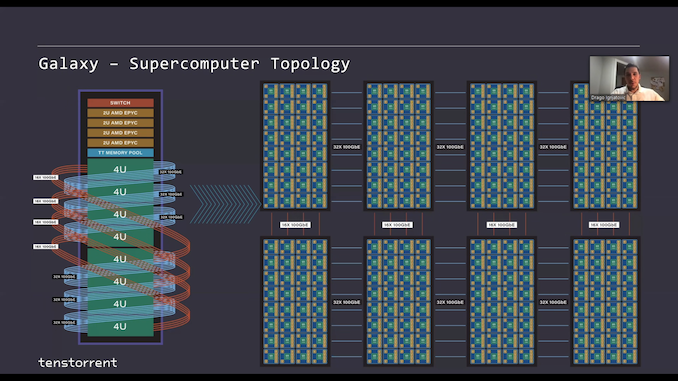
IC: The subsequent technology Wormhole seems immense. You’ve known as it a processor and a swap multi functional, because the 16 x 100 GbE ports enable for seemingly limitless scaling. The presentation on the Linley convention was fairly spectacular, showcasing 24 of those 75 W chips in a single rack unit, chip to chip enabled by means of Four of these connections in a mesh, after which server to server with a number of terabits, after which rack to rack much more, whereas conserving the identical native 100 GbE chip-to-chip connectivity no matter location. What's the function of Wormhole?
LB: That’s a loaded query! It would rely quite a bit on the workload that you just're working, and the form of prototypical ‘mega-workload’ of in the present day are these transformer fashions, like GPT-3. GPT-Three might be essentially the most well-known member of that household proper now, and the way in which individuals have a tendency to prepare these is by a bunch of replicated modules. In these modules there are encoders and decoders, they usually're very related. The mannequin is a stack of those - an extended stack of them. So for a mannequin like that, you'll be able to actually take the 2D mesh very, very far.
The questions that come up are whether or not the module or encoder suits on to your particular {hardware} structure. So often for many different architectures that we now have been watching you need fairly excessive bandwidth communication throughout the encoder or throughout the decoder, after which the bandwidth wants on the boundary of those containers are type of extra restricted. So what has emerged are options the place you should have a shelf which is sort of a 2U or a 4U, and also you map one in every of these blocks onto them. Then there can be community communication between these computer systems, they usually coincide with the sting boundaries there. So one of many messages we tried to present at Linley (the Linley Convention) was that the necessity to match the encoder or decoder module to a particular 2U/4U system is probably detrimental. It is a boundary that forces mannequin designers to undertake a sure set of sizes in a sure mannequin structure with a purpose to match the machine.
So one of many issues we did was to take away that boundary. We created a uniform grid, it is actually giant, and you'll mainly place all the pipeline onto that. There aren't any bandwidth cliffs, and there is nothing that you just actually have to be tremendous nervous about as you might be designing fashions. One of many massive messages that the blokes at Linley tried to present was that we have tried to take away the constraints from the mannequin designers for this. There was a type of synthetic restrict to at least one field per one module of your mannequin which has emerged. So so long as the fashions do not change the 2D mesh abstraction is prone to maintain up fairly properly. The fashions themselves are 2D-ish, they usually're type of left to proper with information stream, so you do not see quite a lot of random connections skipping round from the start to the top of the mannequin and so forth. So so long as that holds the 2D mesh, it's a fairly good abstraction.
JK: You recognize, there is a humorous factor - your mind is, I simply learn this just lately, your cerebral cortex is 1.Three sq. ft. And it is primarily, it is a flat skinny layer however solely six neurons excessive, nevertheless it's constructed out of those columns of about 100,000 neurons, and it's extremely uniform. So it is a little bit 3D-ish. It is very massive in two dimensions, however solely six deep within the different dimension. That is been steady for, you recognize, tons of of tens of millions of years.
IC: However the mind has had tons of of tens of millions of iterations to get it to the place it's in the present day. There have additionally been tons of of tens of millions of iterations of getting it mistaken.
JK: Yeah, that is for positive! That is why [at Tenstorrent] we're iterating yearly, and we're going be at this for some time. It is fairly cool. The arithmetic proper now's being formulated as 2D matrices, and the 2D mesh is pure for that, and the way in which the graph compilers partition stuff is fairly pure for us. The N3/N2 works in our favor.
However eliminating the bogus boundaries, similar to solely having eight chips and also you may solely design for eight chips, whereas we're constructing this actually cool field with Wormhole, with much more chips in it. It has sufficient bandwidth that we will then make that as a part of our mesh going ahead. There are additionally trade-offs to consider, similar to if or when one of many cabinets breaks, and the way do you restore it. Like, how do you wish to construct the mesh? Folks have plenty of totally different opinions about that, and primarily at that degree we're versatile, however yeah, there's one thing highly effective about meshes. Then you need to do quite a lot of work on reliability and redundancy and rerouting, there are every kind of fascinating particulars on there.
IC: With the 2D mesh idea, it’s nice that you just carry up this six neuron excessive mini-3D mannequin. Is there any need or roadmap you suppose on AI compute to maneuver to a extra 3D model?
JK: It might be pure for us, as a result of our Tensix cores are literally large enough that they may do the native 3D a little bit bit. So if any individual needed to say they need a mesh to be a few layers deep, we may try this fairly naturally. For full three-dimensional, we would have to actually take into consideration how the graph partition labored. However you may as well plot a 3D factor onto a 2D factor.
IC: The place do you see Wormhole’s limits because the calls for on AI develop? Localized SRAM, on-chip reminiscence, compute-per-Tensix core, or bandwidth, or one thing else?
JK: That’s a fairly good query.
LB: As issues stand, with in the present day's crop of workloads it's fairly properly balanced. It is considerably troublesome to foretell what's the first parameter that we will find yourself tweaking as issues change. Between Wormhole and Grayskull, we have truly modified the combo of compute and reminiscence within the newer core, so we now have extra reminiscence per core, and we now have extra compute per core than earlier than, in addition to a little bit fewer cores per chip. In the end that was type of pushed by simply actually measurements. What we see as we compile workloads has advanced between the 2 chips. Your level is certainly true and that workloads evolve, and the suitable steadiness of compute to reminiscence to I/O bandwidth additionally goes to evolve, however what precisely goes to alter first? It is type of onerous to foretell.
IC: In one of many diagrams in your current Linley presentation Ljubisa, you have got a rack of Wormholes, after which you have got one other rack of Wormholes, and the concept is that you just span out a number of racks of Wormholes, all related by 100 gigabit Ethernet. We're speaking 100s of connections server to server and rack to rack. At what level does the price of the cables develop into greater than the price of the chips, as a result of these cables are costly!
LB: We’re not there but! Jim made a humorous comment after we reviewed our inside Wormhole system a few weeks again. Within the Wormhole programs we don’t have any host processors, so there isn’t any Intel chip in there, or any AMD chip in there, working any type of Linux. Jim seemed on the BOM (invoice of supplies) price for the machine and he goes ‘properly, I suppose we minimize out the processor prices, however changed it with cables’. [laughs] They’re a non-trivial piece of the price at this level, however they’re nonetheless very removed from reaching to the extent (in price) that the machine studying processors are at.
JK: That is one cause why energy density actually issues. We're constructing this actually dense 4U field partly to save lots of cables. It positively issues. On the flip facet, networking has gotten higher! I keep in mind after we're struggling like loopy to get to 10 gigabit, after which 25 gigabits a second. We have raced by means of 50 gigabit, 100 gigabit, and 400 gigabit due to sign processing on the wires and only a complete bunch of expertise innovation. Community bandwidth has gone up quite a bit, and it is superb that this layer two transport layer which labored at 100 megabits continues to be a fairly good reply at 400 gigabits. It is a actually fascinating expertise whenever you nail the abstraction layer. How far can go? I at all times joke that they should have modified the legal guidelines of physics, as a result of I keep in mind when 100 megabits was a ache, and now we now have 400 gigabits.
IC: Just a few firms have been saying the long run is alongside the built-in silicon photonics line, however the firms which might be doing which have multi-billion greenback budgets. Is one thing like that viable for a start-up like Tenstorrent?
JK: Photonics has been the factor that ‘we will should go to in 5 years’ for 20 years. It is one other a type of fascinating phenomena - it is more durable to construct, particularly when the tempo of innovation on copper has been spectacular. The primary model of photonics can be when is it higher within the rack to make use of photonics than copper, not whether or not it has to go to the chip. The reply nonetheless is determined by how far you are going, and the way a lot bandwidth you have got. They're beginning to do the highest of the rack mega pipes with photonics. However the wires in a rack are all copper, and the economics of the answer are actually clear. It is a type of static issues. It is like individuals mentioned ‘Moore's Regulation is lifeless in 10 years’. Once I realized they have been saying that for 20 years, I made a decision to disregard it, or in some unspecified time in the future examine why individuals had that perception for such an extended time frame. It is truly biblical apocryphal stuff. The world is at all times going to finish in 10 years, as a result of that is when the diminishing return curve runs out.
IC: So what's the way forward for Tenstorrent’s designs? You’re going from Grayskull in 2021 to Wormhole in 2021, to the gen after that - I believe Jim alluded to extra compute, to extra networking and interconnect. What’s the route right here?
JK: We simply introduced with SiFive that we're licensing their cores, and on the following technology we’re placing an array of processors in there. We’re doing it for 3 causes. It allows native community stack type of stuff, similar to Sensible-NIC habits and another issues like that. These cores may run general-purpose Linux, and so that you may wish to simply regionally compute some type of information transformation when you're utilizing the Tensix cores. However the fascinating factor from an AI perspective is that we will put greater CPUs contained in the compute graph on every chip. In order you are computing some consequence, you could wish to run a C program on that information, and it is greater than what the core can do regionally, so we can provide it to a much bigger laptop inside the identical chip.
Once more, it is about the right way to give programmers what they need. They wish to construct fashions, they wish to write code, they usually need all of it to work collectively. They do not wish to have this type of archaic setting the place there’s an accelerator and there is a host and this world is Linux and this world is one thing else. There are many boundaries in AI software program in the present day. We're making an attempt to restrict that type of stuff. So we're doing it by including normal function compute and ensuring that every one the items work very well collectively.
IC: These are SiFive’s X280 RISC-V cores, with 512-bit vector extensions?
JK: Yeah, there’s a pleasant massive vector unit and it has the suitable information sorts that we needed for the computation. So you'll be able to ship the dense 16 bits load over there, and it could actually compute it, and has the great massive vector unit. They (SiFive) are doing quite a lot of work to make it possible for in case you write affordable vectorized code it should compile and run fairly properly. Chris Lattner is over at SiFive now, and he is among the finest compiler guys on the planet. So it provides us some confidence about the place that software program route goes to go. I believe RISC-V is admittedly going to, properly it is already making enormous inroads in all places, however with the following technology stuff with massive vector items and actually nice software program, RISC-V goes to be fairly cool.

IC: Do you are taking a die space hit implementing these additional RISC V cores – is it vital?
JK: In our first one (put up Wormhole), no. We mainly have an array of processors, and we're going to put a column in of CPUs per chip. It’s not massive, nevertheless it has quite a lot of general-purpose compute, and now a part of what we're doing is evolving our chip designs. We're additionally going to evolve our software program stack, and we're keen to do experiments. As a result of it is a actually fast-changing discipline, we predict that is an architecturally fascinating route to go.
IC: Is there any likelihood that a part of your designs can be utilized as form of like, a mixture and match? Can you have got a mesh of earlier technology {hardware} related to next-generation {hardware}. Has that ever come up? Or do you suppose clients on this area will simply bulk change from one to the following?
JK: The software program we're constructing is designed to be as suitable as attainable. So in case you like Grayskull, and then you definitely go to Wormhole, you'll be able to construct a 16 Wormhole chip machine that works fairly equally (on the identical software program), nevertheless it scales higher. Then after we go to the following chip, all that software program you created goes to work, however then if you wish to add extra performance you are able to do that too. If you wish to add extra performance, you’re going to need the brand new one.
However computation depth goes up, community bandwidth can be going up. So yearly you want a brand new aggressive product, however in a semiconductor world you are likely to promote components for 2-Four years, as a result of as you go into manufacturing the prices come down. You must have a pricing technique. We anticipate to maintain promoting the first-generation and second-generation, they're nonetheless good stable components. However we'll maintain engaged on new options for the following spherical.
IC: Tenstorrent is presently partnered with GlobalFoundries for the primary couple of chips, Grayskull and Wormhole. Is it nonetheless going with GlobalFoundries transferring ahead, or are you creating relationships with different foundries?
LB: We're creating relationships with different foundries, primarily as a result of need to do some chips sooner or later in even decrease geometries than what we’ve been utilizing.
IC: One of many points with VC-funded AI firms is the dearth of a ample roadmap, or the necessity to purchase funding for that roadmap. How ought to traders take a look at Tenstorrent from that perspective?
LB: Our roadmap has been type of pretty static and constant over time. We have been in a position to predict what we will do a number of years out, and to date we have simply been doing that. Fortunately sufficient, we have additionally been in a position to purchase the funds which might be wanted to maintain it, so you might say that it has been roughly break up up into epochs. We talked in regards to the basement factor and the workplace within the dangerous a part of city and people type of coincided with quantities of funding. After that, we moved into an precise correct working workplace, there was one other epoch with one other set of funding. That is after we did our first chip, the take a look at chip. So just about each chip has coincided with a spherical of funding, and within the first couple of years, they've coincided with a transfer as properly.
We just lately accomplished a pretty big spherical of funding, which we've not fairly, you recognize, publicized simply but, in truth, I believe that is the primary public dialog we're having about it (Tenstorrent has since introduced a $200m funding spherical on Could 20th). What I'll say is that it utterly allows our roadmap for a few years. It allows not solely our subsequent one, however a few our presently deliberate future chips. Basically we're in a spot the place we must always have the ability to ship the whole lot we're planning to ship, and by that time, we're hoping that it may be self-sustaining.
JK: I am going to provide you with a quantity - we did a take a look at chip and two manufacturing chips (Jawbridge and Grayskull) for $40 million whole, and we now have an awesome software program staff. The genesis of it's actually fascinating. We've individuals from the FPGA world, from AI and HPC, and the mix of their abilities and perception plus the {hardware}/software program match – all of it signifies that our software program staff is method smaller than anyone else’s, and our software program stack is far more efficient and environment friendly. In order that has saved us a boatload of cash - we do not have to announce that we're hiring 300 software program individuals to make our {hardware} work as a result of we made good architectural decisions, each on the software program and on the {hardware} degree. That has made us efficient.
The smaller geometry chips are costlier to do, by about 2X. So it may elevate our burn charge a bit. However we now have a fairly good line-of-sight to being worthwhile on the cash we have already raised, so we really feel fairly good about that. That is partly as a result of we have been environment friendly to date, and we're not carrying round massive technical debt on software program or {hardware}. I believe that is a reasonably large distinction from another AI start-ups.
IC: Did bringing Jim on as CTO trigger further curiosity within the firm? I imply, not solely from the likes of us within the press however from potential traders or clients?
LB: Completely! I imply it is precisely the identical throughout the spectrum - Jim has a repute of any individual who's each uniquely in a position to decide the standard of a technical answer, in addition to understanding the way you truly carry it out to clients to go promote it. He can go from a technical product or technical idea in an engineering proof-of-concept sort story, to one thing that is truly transport in giant quantity. I imply it has been a really binary factor, from zero to at least one, just about since Jim joined. We have been in a position to type of get within the door rather more simply at complete number of locations, not solely the press, however traders and clients as properly, for positive.
JK: I’ve labored at two start-ups, SiByte after which P.A. Semi. I’ve met actually tons of of consumers, promoting processors. They had been each community processors, and promoting into embedded markets. However I’ve coated a really numerous area. I've quite a lot of expertise of assembly with individuals and determining what they're truly doing, what they really want, after which determining if we're doing that, and if we're not doing that, why aren't we doing it? Then suppose what ought to we do about it?
So it has been enjoyable - I do not know the way many individuals [I’ve talked to] since I've joined on, maybe 30 to 40 totally different firms. They're actually numerous, you recognize, there's the sting, the autonomous facet, the datacenter individuals, there's picture processing, there's massive cloud computation. The area is admittedly numerous. However all of them come again to the identical factor - compute depth, the correct quantity of DRAM, the correct quantity of networking, and software program that works. They actually need to have the ability to do stuff.
We're speaking to a few massive firms who're annoyed with the present closed ecosystem, and they're programming firms, so they need to have the ability to program the {hardware}. We're additionally pondering that we wish to program the {hardware} too, so what's the massive downside? However there are many secrets and techniques on this enterprise, so we're telling them about how our stuff works, and we will open up each the {hardware} and software program specs fairly a bit. They're tremendous enthusiastic about that, so we will get the door open, however the doorways do not stay open except you have got one thing to say.
IC: So is Tenstorrent large enough to have the scope to work with a number of very particular clients on their very particular workloads for the {hardware}? An enormous factor about AI firms is basically helping their clients with the {hardware} and serving to them program it to get the very best out of it. The place does Tenstorrent sit there?
LB: There are two sides to that query. One is how a lot particular person ‘assist’ and customization we will maintain. The opposite one is extra of a technical architectural query. [It comes down to] how immune to the have to be personalized for each given use case. While you peel the onion, that feeds all the way in which into {hardware}, and the software program does not exist in isolation. But it surely's like Jim talked about earlier, we now have a reasonably small staff, partly as a result of we actually did not want a much bigger staff to do what we needed, but in addition partly as a result of massive groups are literally onerous. Managing a staff of 300 individuals and successfully contributing to the identical codebase is definitely one thing that not too many individuals or locations are able to. So we tried very very onerous, each step of the way in which, to make our software program such that it may be maintained by a small quantity of individuals, whereas nonetheless assembly the targets that the world was in entrance of us.
One of many unintended effects is that there is little or no guide intervention relating to machine studying. For those who herald a neural community that we've not seen earlier than, we now have tried to make it in order that the chance that we actually have to do a bunch of guide tweaking is low. Then if we do have to do it, it’s simpler. Like that it is one thing we will get executed in a few days, and never have a three-month burn on. I believe we have materially succeeded there. So our software program stack is fairly properly structured, and fairly resilient to new workloads. Additionally it is small - the quantity of it's low. We're speaking a couple of 50,000 strains of code type of product, not a 5 million one. That makes it a bit simpler.
Alternatively, there may be nonetheless a bunch of labor to do for every buyer. Folks often wish to combine into present software program stacks, into options that span greater than machine studying. For instance, you have got video coming in on a digital camera, and whoever needs to purchase an inference engine for that video they wish to combine it into their pipeline. So they need video coming in over IP, decoding it, feeding it into us, adorning it with containers, or conclusions, re-encoding it, probably connecting to cost platforms, all kinds of ancillary stuff that is utterly unrelated to machine studying.
So for this form of factor we're build up a staff internally to assist this form of work. That is type of a part of the answer, and we will definitely have the ability to maintain this type of work with a number of giant clients. However in the long run you actually need to construct up an ecosystem of collaborators for this type of factor. I do not suppose even the heavyweight firms on this area truly pull all of this by themselves. Normally it's kind of of an ecosystem-building train, and we now have that in our plans, nevertheless it's a step-by-step course of. First you need to actually crush the machine studying workloads, persuade all people that you've got executed that, and you've got one thing nice. Then you definately type of throw quite a lot of effort into constructing an ecosystem, so all of that’s coming down the pipe.
JK: We wish to scale the assist finish of it, not the core compiler facet. If we try this half proper, it needs to be a extremely good tight staff. And I noticed this at SiByte - there have been three working programs we needed to assist: the Cisco working system, Linux and Wind River. Then we needed to set the drivers on high of that, and as soon as we nailed that image, plenty of totally different individuals may do every kind of stuff. As a result of as soon as the broad assist bundle is there, they're then including their very own software program on high of that platform which was fairly easy. We had 100 clients with a small assist staff, however till we discovered the mechanics of the items, it appeared sophisticated, as a result of all people appears to need one thing totally different. However as soon as we obtained the abstraction layer proper in the suitable working system and the suitable set of drivers, then lots of people may do various things with it.
IC: Talking of personnel, at AMD Jim was the boss and Ljubisa was a part of Jim's staff. This time round, it’s Ljubisa that’s the CEO, and Jim’s the underling. How is that dynamic working? Is it higher or worse? How does it come throughout day-to-day?
LB: That’s not an correct portrayal of the way in which we now have it arrange! We’ve agreed to do that factor as companions for essentially the most half. So Jim is definitely not an underling to me. In actuality, if something, you recognize, Jim’s any individual that’s senior to me in each method conceivable. So I believe it’s cool that we’re doing this in partnership, however actually if anyone’s type of taking route at factors or ambiguities, it’s me.
JK: Ljubisa created Tenstorrent and his staff, his authentic founders after which the core staff are some actually nice individuals there. We talked quite a bit about what we must always do, and you recognize, I believe it might be completely nice if we IPO and Ljubisa’s the CEO, and I am supporting that 100%. We get alongside actually good, we discuss every single day, and there are some issues we divide and conquer. He is been actually targeted on the software program stack, and I’m targeted on the following technology half. There is a bunch of architectural options that we work on - we get collectively, we discuss it, and we are saying ‘you do that, I am going to try this’. Thus far, that is been working very well. There's some enterprise stuff that I have been targeted on much more, as a result of I am actually occupied with how that is going to go collectively and go to market. However yeah, and with traders we largely each discuss to them, then that is fairly good, and we cowl totally different areas. So you recognize, to date, so good.
IC: That’s truly fairly good as a result of it leads me onto asking Jim about what precisely what you’ve be doing at Tenstorrent to date. On the level you joined, Wormhole was already within the means of going to fabs, being taped out, or no less than within the remaining levels of design. So in my thoughts you’re engaged on the following technology and the technology after that, however now you’re telling me you’re doing quite a lot of the enterprise facet as properly?
LB: Jim’s an awesome gross sales man. I at all times figured him to be a persistent dude, any individual that is aware of expertise, however frankly I used to be shocked by his degree of consolation in these conferences with clients.
JK: I used to be at two start-ups the place we had a extremely good staff, with a man may get all of the doorways open. We had me that was speaking about structure, with a software program man, with a system board man, we simply had a staff. We'd go discuss to individuals and go clear up their issues, and whenever you try this, you study quite a bit. The factor I like is ‘oh, that is what you are doing with our chip! Holy crap, we weren't fascinated by that in any respect!’.
I have been instructed at numerous factors in my profession to deal with that high-level image of managing, however I at all times prefer to get into the small print, as a result of that is the place you study the whole lot, and then you definitely combine it collectively after which do one thing with it. So speaking to clients is enjoyable, particularly in the event that they're good they usually're making an attempt to do one thing new, so I like to try this type of stuff. I prefer to work in partnerships, you recognize, like Pete Bannon and I've been working collectively on and off for 30 years. We labored on the VAX 8800, EV5, we labored at P.A Semi after which Tesla, and Apple. Jesus, is that what number of locations [with Pete]! Dirk Meyer and I labored on at DEC and AMD collectively for years. You recognize, I play fairly properly with others!
It’s solely just lately that I discovered myself being the VP. Raja Koduri and I labored collectively when he was at AMD, and I used to be at Apple. Then he got here to Apple, after which I went to AMD, then he went again to AMD. He went to Intel, after which I went to Intel. So you recognize we labored on an entire bunch of tasks collectively so I am fairly used to, I'd say, ‘intense’ mental collaboration. Then you definately discover you’re form of good at various things - like Dirk was method higher at execution and particulars, and I'd provide you with loopy concepts. He would take a look at me like ‘I do not know why you wish to try this, however I am going to strive it’. We had quite a lot of enjoyable doing stuff. I wrote the HyperTransport spec, and the unique spec was like 16 pages. I despatched it to Dirk, and Dirk mentioned ‘Jim, I understand how you suppose – do you thoughts if I fill in a number of particulars?’. Three days later I obtained a 60-page spec again that truly seemed like one thing {that a} human being may learn. He was 100% proper, as a result of he truly did know what individuals wanted to see in a spec. So yeah, I like that type of stuff, it is actually enjoyable.
IC: I believe you have got cultivated that picture of mad technical scientist - let’s strive a bunch of stuff and any individual else can fill me in with the small print, however let’s fill in a bunch of stuff. I imply how typically nowadays do you end up within the nuts and bolts of the design versus that extra form of holistic roadmap?
JK: On a regular basis.
IC: On a regular basis?
JK: Yeah, I don’t wish to go into too many particulars, however once I was at Intel, individuals had been shocked a Senior VP was grilling individuals on how they handle their batch queue, or what the PDK is, or what the qualification steps had been, or how lengthy the CAD flows took to run, or what the dense utilization was within the CPU, or how the register file was constructed. I do know particulars about the whole lot, and you recognize I care about them, I truly actually care. I need them to look good.
A buddy of mine mentioned, if it does not look good, it isn’t good. So whenever you take a look at the format of a processor, or how one thing is constructed, it is obtained to be nice. You'll be able to't make it nice if you do not know what you are doing. It’s dangerous if any individual provides you want a five-level abstraction PowerPoint slide that mentioned, issues are going good, and we're bettering issues by 3% per 12 months. I have been in conferences the place any individual mentioned 5% higher, and I mentioned ‘higher than what? Higher than final 12 months, or higher than the absolute best, or higher than your first-grade challenge?’. They actually did not know what - they'd been placing 5% higher on the slide for thus lengthy, they forgot what it was. So yeah, you need to get the small print.
If you are going to be within the expertise enterprise in any method, form, or kind, and you need to get to the small print. I believed I used to be good at that, after which I met Elon Musk. Holy crap. For him the small print began at atoms. Possibly decrease, I do not know. However like, what I believed was first precept pondering wasn't near his first precept pondering, after which I obtained my ass kicked severely about doing that. But it surely was actually nice, I actually like to try this. I hope that once I interact with engineering groups, they begin to get that engineering is enjoyable, and the small print matter, and there is an abstraction stack - there's the excessive degree, there's the medium, and there is a low degree. Sure, you do have to know quite a bit about all of them, as a result of then you'll be able to work out how to make things better. You'll be able to't repair one thing easy like ‘laptop too sluggish’ - what are you going to do if it is too sluggish? For those who may go into 1000 particulars, there's every kind of stuff to do if you recognize the small print.
IC: I’m shocked that folks would surprise why you’re asking detailed questions on, register file and cache use and such, as a result of that is stuff that you just’ve been doing for thus lengthy. It type of appears bizarre to me, it’s nearly as if the particular person you had been talking to didn’t know who you had been?
JK: Yeah, however the positions get related to technical degree. My staff at Intel was 10,000 individuals, proper, so that you spend quite a lot of time on group charts and budgets, and every kind of admin, after which it is simple to seek out your self simply doing that and saying you’ll hand off management for a challenge to this particular person or this particular person and that. However the issue is there's so many issues which might be cross-functional – I wish to know what the fab is doing, how does the PDK work, how does the library work, how does the IP staff work, how does the SoC integration work, how does the efficiency mannequin work, how does the software program work. Then you definately discover out that if you cannot deep dive into all these items, dangerous issues occur.
My father labored in GE when Jack Welch ran GE, and he mentioned Jack may go to any a part of GE and inside a day and unravel it. He obtained credited with an entire bunch of enterprise innovation, however I heard from many individuals that Jack may unravel something. I learn his guide Straight From the Intestine years in the past, and I believed, properly, I would prefer to be that type of particular person you recognize - if I'll handle individuals, I would prefer to be the type of particular person to get the underside of something.
IC: It’s well-known that you just’ve been bouncing from firm to firm each few years….
JK: Nooo, that’s a fantasy!
IC: That's the normal notion, so it should ask, as a result of Ljubisa alluded to your age earlier, as being extra senior - is Tenstorrent your remaining dwelling, because it had been? When do you see your self retiring?
JK: I'll be right here ceaselessly, however I most likely can have a number of different issues occurring. And, you recognize, I used to be speaking to some buddies a couple of quantum qubit firm, which I believe is hilarious. Then I've a few different buddies the place we have been brainstorming on the right way to do a brand new type of semiconductor start-up, that is like 1,000,000 instances cheaper than the present stuff. There's different stuff I am occupied with, however at Tenstorrent, our mission is to go construct AI for everybody - programmable chips that folks can truly use. That is a many-year effort.
IC: So will you ever retire?
JK: I learn a guide someplace that from retirement to demise is 10 years, and I wish to dwell to be 100, so I’ll retire at 90, I suppose?
IC: You hear that Ljubisa, you have obtained Jim till he’s 90.
LB: That sounds nice! It’s not a shock, we haven’t mentioned it, however in case you ask me I'd have mentioned one thing related.
JK: I love to do stuff - I snowboard with my children, and I'm going kite browsing in Hawaii. I prefer to run and goof round. I've obtained stuff to do, however I prefer to work and I like expertise, and it is actually fascinating. It is superb, you recognize that periodically individuals suppose today is the top of this, or the top of that, and holy cats you recognize the AI revolution is larger than the web. It may change how we take into consideration the whole lot, how we take into consideration programming, how we take into consideration computing, how we take into consideration graphics, photographs, every kind of stuff. So yeah, it is a actually fascinating time to be a part of expertise.
IC: Is there something about Tenstorrent that you really want individuals to know that hasn’t actually been mentioned wherever?
JK: Effectively, we're hiring. So if individuals wish to! I actually love engineers who would like to do stuff which might be actually hands-on. I employed a bunch of senior CPU guys, and the very first thing they did is that they began citing the DB infrastructure and constructing a mannequin, and attending to the underside of it. So you recognize if you wish to handle a bunch of individuals and sit round making PowerPoints, please do not apply to us. However in case you're a technologist and also you wish to be hands-on and do actual work, that is nice. Or in case you're younger and good, you wish to work onerous and study one thing from actually good individuals, do it. How many individuals had been on the staff that constructed Grayskull? We constructed a 700-millimeter world-class AI chip with 15 individuals?
LB: That is proper.
JK: It is unbelievable. So if you wish to discover ways to construct stuff, this might be a superb place. So ship us your resume. They lastly prodded me to hitch LinkedIn. I do not actually know the way that works, however they inform me that is going to assist me join with individuals and rent.
IC: It actually doesn’t!
JK: I do not know! The factor I actually like is it retains saying ‘your community says you recognize this particular person’ - I used to be like I labored with him a pair years in the past, and he was nice. So I despatched him a message, ‘hey, you wish to come work with us?’ It has been type of enjoyable, it is like a little bit reminiscence lane stroll for me due to how the algorithm works. However yeah, I am not a social media particular person in any respect. I identical to to speak about issues, and I believe I've despatched out like three tweets in my complete life. It’s fairly enjoyable.
IC: You're in Toronto, Austin, and the Bay Space proper now?
JK: That’s proper, yeah, we did. We took a model new workplace in Santa Clara. 10,000 sq. ft, it’s lovely. We've a suggestion on a brand new workplace in Austin, which goes to be nice. I like having a very nice place to work. Once I go to work, I need it to look good. I nonetheless keep in mind once I went to Apple, it was hilarious. They modified the font on one of many Mac manuals, in order that they repainted the fonts on all of the indicators across the campus to match. That spotlight to element simply cracks me up, nevertheless it was a very nice place to work and it was cool. So yeah, we now have three places of work, that are all going to be good locations to work.
Many because of Ljubisa, Jim, and Christine for his or her time.
Additionally because of Gavin Bonshor for the preliminary transcription.
Posting Komentar
Posting Komentar